Coerenza della cache: definizione e meccanismi nei sistemi multiprocessore
Scopri la coerenza della cache: definizione, problemi e meccanismi nei sistemi multiprocessore per garantire prestazioni e integrità dei dati nelle CPU multicore.
Una cache può essere utilizzata per migliorare le prestazioni di accesso a una data risorsa. Quando ci sono diverse cache per la stessa risorsa, come mostrato nell'immagine, questo può portare a problemi. La coerenza della cache o Cache coherency si riferisce a una serie di modi per assicurarsi che tutte le cache della risorsa abbiano gli stessi dati, e che i dati nelle cache abbiano senso (chiamata integrità dei dati). La coerenza della cache è un caso speciale della coerenza della memoria.
Ci possono essere problemi se ci sono molte cache di una risorsa di memoria comune, poiché i dati nella cache potrebbero non avere più senso, o una cache potrebbe non avere più gli stessi dati delle altre. Un caso comune in cui il problema si verifica è la cache delle CPU in un sistema multiprocessing. Come si può vedere nella figura, se il client superiore ha una copia di un blocco di memoria da una lettura precedente e il client inferiore cambia quel blocco di memoria, il client superiore potrebbe essere lasciato con una cache di memoria non valida, senza saperlo. La coerenza della cache è lì per gestire tali conflitti e mantenere la coerenza tra cache e memoria.
Galleria di immagini
3 Immagini

Cause dei problemi di incoerenza
- Più processori o core mantengono copie locali della stessa locazione di memoria per ridurre la latenza degli accessi.
- Un core può aggiornare la propria copia senza aggiornare immediatamente le altre copie presenti nelle cache degli altri core.
- Operazioni di scrittura non coordinate possono lasciare copie diverse in stati diversi (valide, invalide, sporche), portando a letture errate o a risultati non deterministici.
Principi di base e obiettivi
- Assicurare che, per ogni locazione di memoria condivisa, tutte le cache vedano aggiornamenti in modo coerente secondo le regole definite dal protocollo di coerenza.
- Mantenere l’integrità dei dati, cioè evitare che letture successive restituiscano valori obsoleti non riconciliati con le scritture effettuate da altri processor.
- Bilanciare correttezza e prestazioni: i meccanismi devono introdurre il minimo overhead possibile in termini di traffico e latenza.
Meccanismi principali
I meccanismi usati nei sistemi reali ricadono in due grandi famiglie.
- Snooping (o bus-based): ogni cache “annusa” il bus di memoria e osserva le transazioni fatte dagli altri soggetti. Se una cache vede una scrittura sulla locazione che ha in copia, può invalidare o aggiornare la sua copia. Protocollo classico: MESI (Modified, Exclusive, Shared, Invalid).
- Directory-based: una struttura centralizzata o distribuita (directory) tiene traccia di quali cache possiedono copie di ogni blocco di memoria. Le richieste di lettura/scrittura consultano la directory, che coordina invalidazioni o aggiornamenti. È più scalabile dei sistemi basati su snooping quando ci sono molti core.
Strategie di sincronizzazione dei dati
- Write-through: ogni scrittura nella cache viene immediatamente propagata alla memoria principale. Semplice ma genera molto traffico di memoria.
- Write-back: le scritture vengono effettuate solo nella cache e il blocco diventa “sporco” (dirty); la scrittura in memoria avviene solo quando il blocco deve essere rimosso dalla cache. Riduce il traffico ma richiede meccanismi per informare le altre cache (invalida/aggiorna).
- Invalidazione vs Update:
- Invalidazione: quando un core scrive, le copie nelle altre cache vengono invalidate; i lettori successivi devono rileggere dalla memoria o dalla cache del writer.
- Aggiornamento: la scrittura viene propagata alle altre cache che aggiornano la propria copia. Riduce miss di lettura successive ma aumenta il traffico di scrittura.
Protocollo MESI (esempio)
Il protocollo MESI è uno dei più diffusi nelle CPU moderne. Ogni blocco di cache può essere in uno dei quattro stati:
- Modified: la copia nella cache è diversa dalla memoria principale (è sporca) e nessun'altra cache ha la stessa copia.
- Exclusive: la cache ha una copia pulita esclusiva (uguale alla memoria) e nessun altro la possiede.
- Shared: la copia è pulita e può essere presente anche in altre cache.
- Invalid: la copia non è valida.
Problemi correlati e ottimizzazioni
- False sharing: quando due variabili diverse, usate da thread diversi, si trovano nello stesso blocco di cache; scritture indipendenti provocano invalidazioni/incoerenze e degradano le prestazioni. La soluzione è spesso a livello di layout dei dati o padding.
- Ordinamento della memoria: la coerenza della cache non garantisce automaticamente l’ordine visibile delle operazioni a livello di programma; per questo esistono modelli di memoria (strong/weak ordering) e primitive come memory fences/barriers che i compilatori e l’hardware devono rispettare per sincronizzazione corretta.
- Scalabilità: i protocolli basati su snooping scalano male su centinaia o migliaia di core per via del traffico sul bus; le directory distribuite o le gerarchie di cache sono utilizzate per sistemi molto grandi.
Implicazioni pratiche per programmatori
- Usare primitive di sincronizzazione (mutex, atomic, barrier) per evitare condizioni di race; non fare affidamento sul comportamento “magico” delle cache.
- Attenzione al layout della memoria per ridurre il false sharing e migliorare la locality.
- Conoscere il modello di memoria della piattaforma (x86, ARM, ecc.) aiuta a scrivere codice concorrente corretto ed efficiente.
Conclusione
La coerenza della cache è fondamentale nei sistemi multiprocessore per garantire che i dati condivisi rimangano consistenti e affidabili. Esistono diversi meccanismi hardware e software per ottenere la coerenza, ciascuno con compromessi tra correttezza, prestazioni e scalabilità. Comprendere i principi (invalidazione vs aggiornamento, write-back vs write-through, protocolli come MESI, e problemi come il false sharing) è essenziale per progettare sia l’hardware che il software in ambienti concorrenti.

Definizione
La coerenza definisce il comportamento delle letture e delle scritture alla stessa posizione di memoria. Le cache sono coerenti se tutte le seguenti condizioni sono soddisfatte:
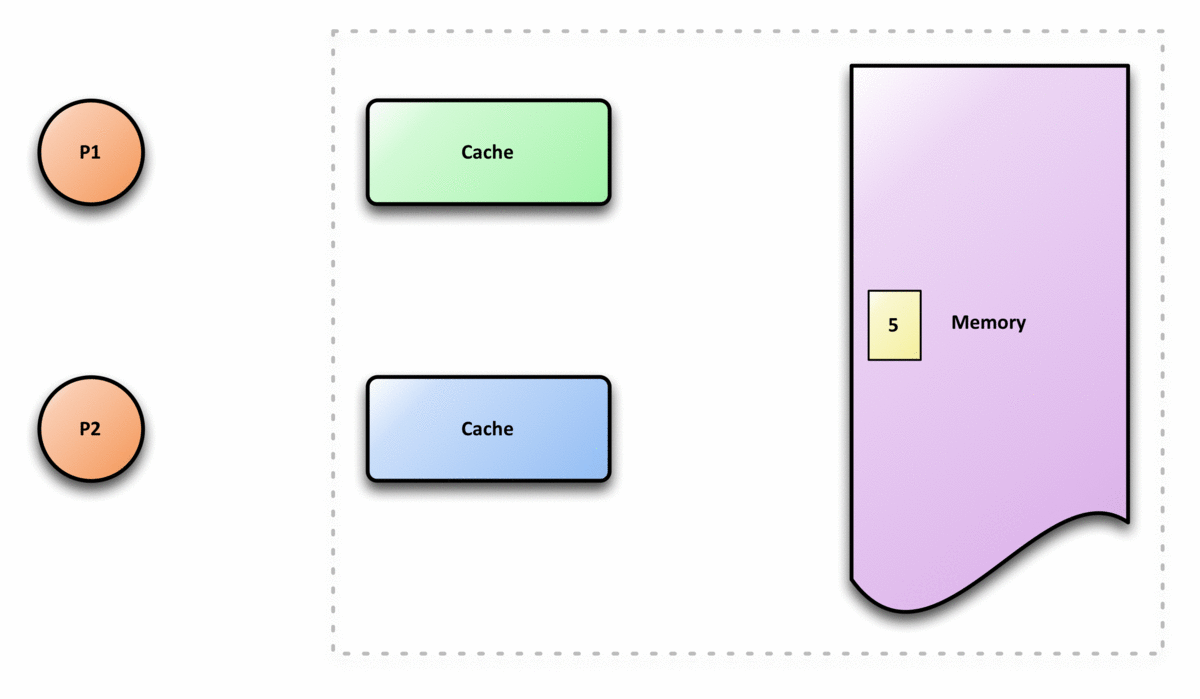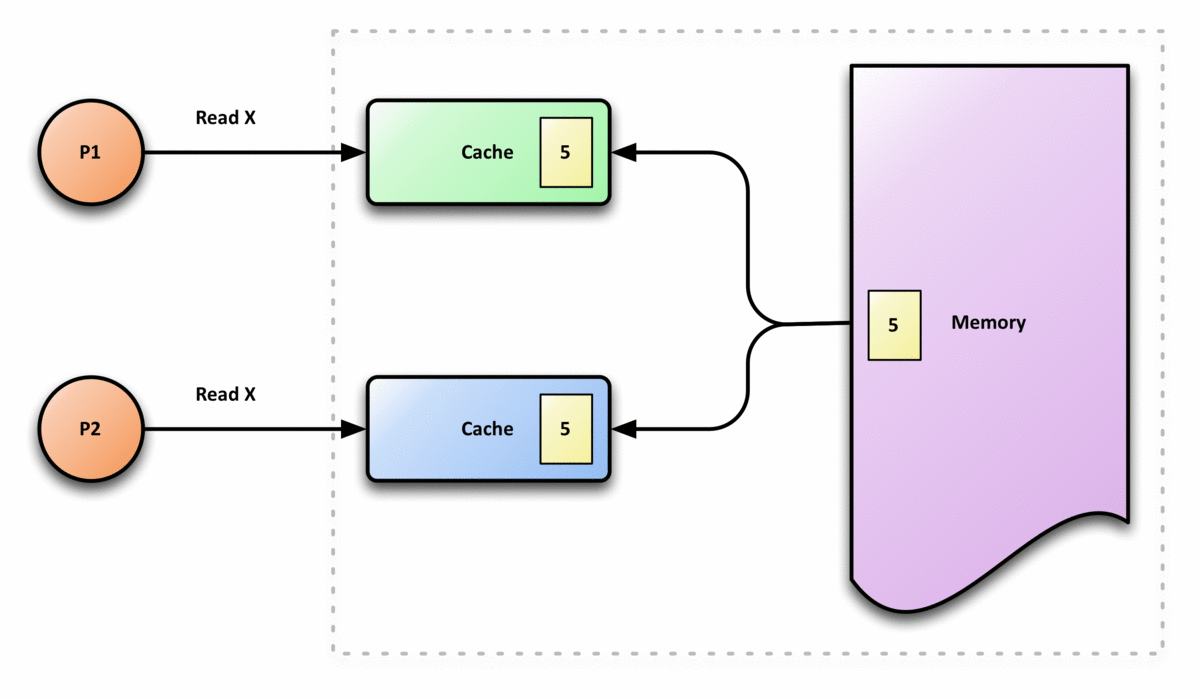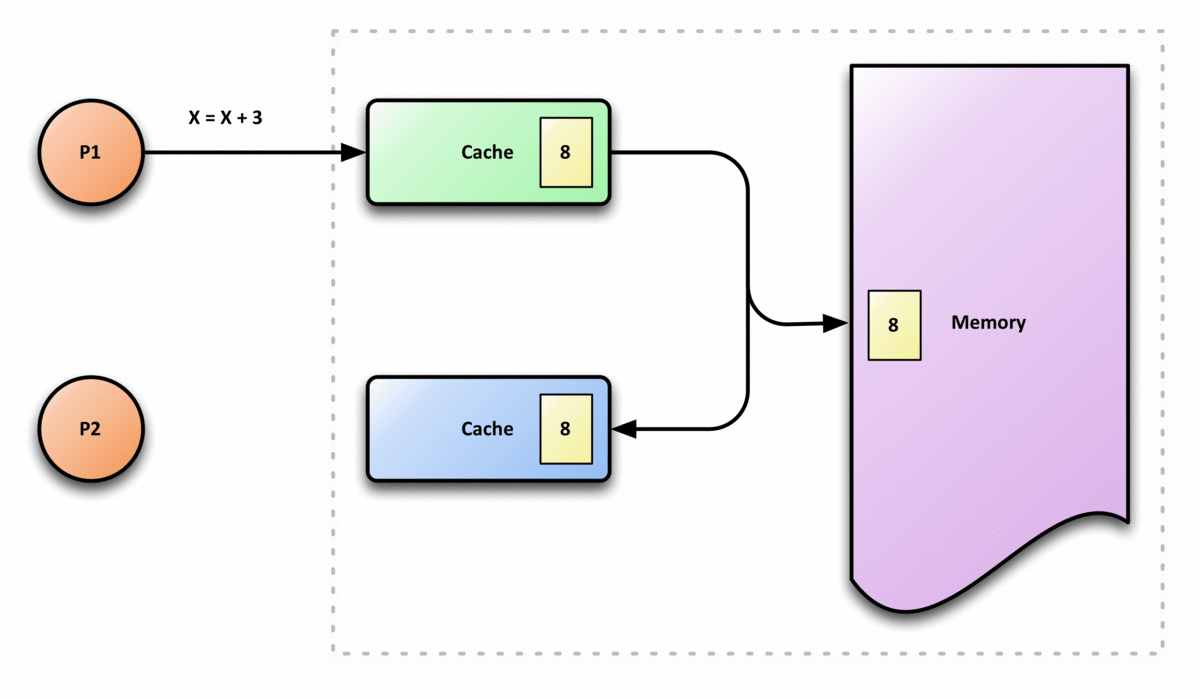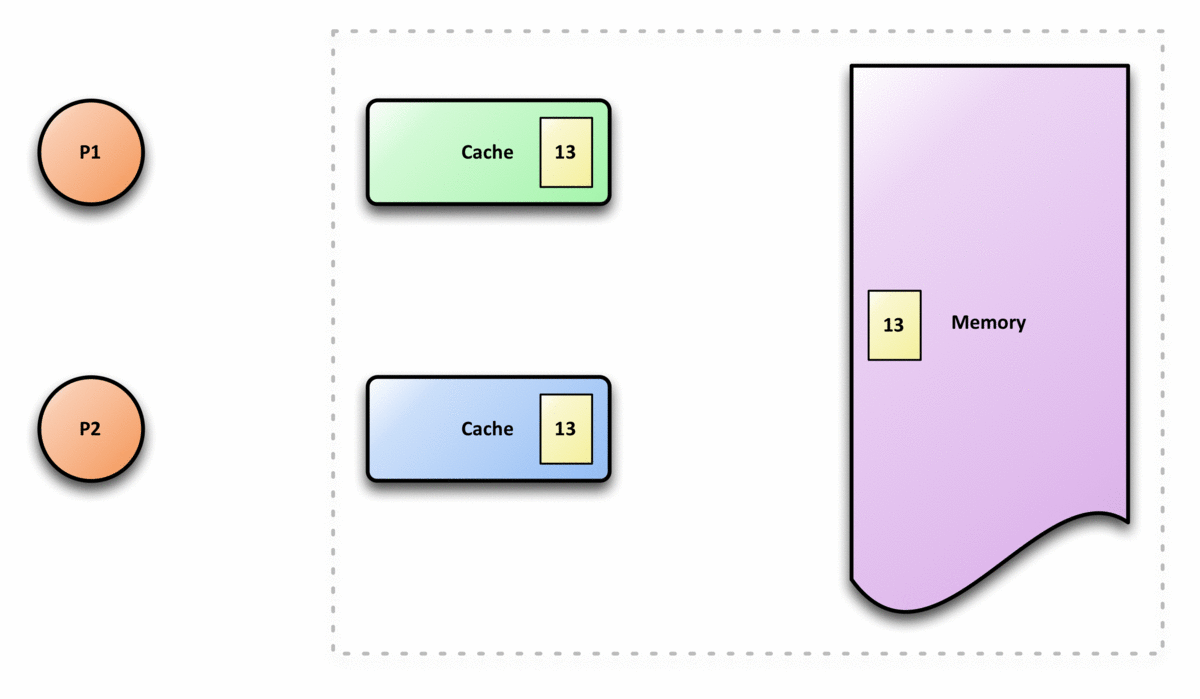
- Quando un processore P legge una locazione X, dopo aver scritto in quella locazione, P deve ottenere il valore che ha scritto, se nessun altro processore ha scritto un altro valore in quella locazione. Questo è vero anche per i sistemi monoprocessori, significa che la memoria è in grado di mantenere un valore scritto.
- Supponiamo che ci siano due processori, P1 e P2, e che P1 abbia scritto un valore X1, e dopo, P2 abbia scritto un valore X2, se P1 legge il valore, deve ottenere il valore scritto da P2, X2, e non il valore che ha scritto, X1, se non ci sono altre scritte tra i due. Questo significa che la vista della memoria è coerente. Se i processori possono leggere lo stesso vecchio valore dopo la scrittura fatta da P2, la memoria non sarebbe coerente.
- Ci può essere solo una scrittura alla volta in una certa posizione della memoria. Se ci sono più scritture, devono avvenire una dopo l'altra. In altre parole, se la locazione X ha ricevuto due diversi valori A e B, in questo ordine, da due processori qualsiasi, i processori non possono mai leggere la locazione X come B e poi leggerla come A. La locazione X deve essere vista con i valori A e B in questo ordine.
Queste condizioni sono definite supponendo che le operazioni di lettura e scrittura siano fatte istantaneamente. Tuttavia, questo non accade nell'hardware del computer a causa della latenza della memoria e di altri aspetti dell'architettura. Una scrittura del processore X potrebbe non essere vista da una lettura del processore Y se la lettura viene fatta entro un tempo molto piccolo dopo che la scrittura è stata fatta. Il modello di coerenza della memoria definisce quando un valore scritto deve essere visto da una successiva istruzione di lettura fatta dagli altri processori.
Meccanismi di coerenza della cache
- I meccanismi di coerenza basati su directory mantengono una directory centrale di blocchi in cache.
- Lo snooping è il processo in cui ogni cache controlla le linee di indirizzo per gli accessi alle posizioni di memoria che sono nella sua cache. Quando si osserva un'operazione di scrittura su una locazione di cui una cache ha una copia, il controller della cache invalida la propria copia della locazione di memoria snoopata.
- Snarfing è quando un controller della cache guarda sia l'indirizzo che i dati nel tentativo di aggiornare la propria copia di una posizione di memoria quando un secondo master modifica una posizione nella memoria principale.
I sistemi di memoria condivisa distribuita imitano questi meccanismi in modo da poter mantenere la coerenza tra blocchi di memoria in sistemi liberamente accoppiati.
I due tipi più comuni di coerenza che sono tipicamente studiati sono Snooping e Directory-based. Ognuno ha i suoi vantaggi e svantaggi. I protocolli di snooping tendono ad essere più veloci, se è disponibile abbastanza larghezza di banda, poiché tutte le transazioni sono una richiesta/risposta vista da tutti i processori. Lo svantaggio è che lo snooping non è scalabile. Ogni richiesta deve essere trasmessa a tutti i nodi di un sistema. Man mano che il sistema diventa più grande, la dimensione del bus (logico o fisico) e la larghezza di banda che fornisce devono crescere. Le directory, d'altra parte, tendono ad avere latenze più lunghe (con una richiesta/avanzamento/risposta a 3 hop) ma usano molta meno larghezza di banda poiché i messaggi sono punto a punto e non trasmessi. Per questo motivo, molti dei sistemi più grandi (>64 processori) usano questo tipo di coerenza della cache.
Domande e risposte
D: Cos'è la coerenza della cache?
R: La coerenza della cache si riferisce alla garanzia che tutte le cache di una risorsa abbiano gli stessi dati e che i dati nelle cache siano coerenti (integrità dei dati).
D: Qual è lo scopo della coerenza della cache?
R: Lo scopo della coerenza della cache è quello di gestire i conflitti tra più cache di una risorsa di memoria comune e di mantenere la coerenza tra cache e memoria.
D: Quali possono essere le conseguenze della mancanza di coerenza della cache?
R: Senza coerenza della cache, i dati nella cache potrebbero non avere più senso, oppure una cache potrebbe non avere più gli stessi dati delle altre, il che potrebbe causare incoerenze ed errori.
D: Qual è un caso comune in cui si verificano problemi di coerenza della cache?
R: Un caso comune in cui si verificano problemi di coerenza della cache è la cache delle CPU in un sistema multiprocesso.
D: Come funziona la coerenza della cache?
R: La coerenza della cache funziona garantendo che tutte le cache di una risorsa abbiano gli stessi dati e che i dati nelle cache siano coerenti attraverso vari metodi.
D: Cosa si intende per coerenza della memoria?
R: La coerenza della memoria si riferisce alla coerenza dei dati in una risorsa di memoria condivisa.
D: In che modo la coerenza della cache può migliorare le prestazioni?
R: La coerenza della cache può migliorare le prestazioni consentendo un accesso più rapido ed efficiente ad una determinata risorsa.
Articoli correlati
Autore
AlegsaOnline.com Coerenza della cache: definizione e meccanismi nei sistemi multiprocessore Leandro Alegsa
URL: https://it.alegsaonline.com/art/15883