Microarchitettura
In ingegneria informatica, la microarchitettura (a volte abbreviata in µarch o uarch) è una descrizione del circuito elettrico di un computer, unità centrale di elaborazione o processore di segnali digitali che è sufficiente per descrivere compl…
In ingegneria informatica, la microarchitettura (a volte abbreviata in µarch o uarch) è una descrizione del circuito elettrico di un computer, unità centrale di elaborazione o processore di segnali digitali che è sufficiente per descrivere completamente il funzionamento dell'hardware.
Gli studiosi usano il termine "organizzazione del computer" mentre le persone nell'industria dei computer dicono più spesso "microarchitettura". La microarchitettura e l'architettura del set di istruzioni (ISA), insieme, costituiscono il campo dell'architettura dei computer.
Galleria di immagini
1 Immagine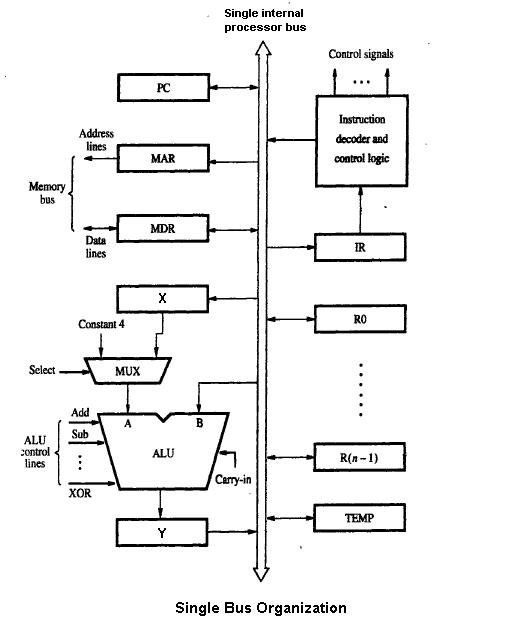
Origine del termine
I computer utilizzano la microprogrammazione della logica di controllo fin dagli anni '50. La CPU decodifica le istruzioni e invia segnali lungo percorsi appropriati per mezzo di interruttori a transistor. I bit all'interno delle parole del microprogramma controllavano il processore a livello di segnali elettrici.
Il termine: microarchitettura è stato usato per descrivere le unità che erano controllate dalle parole del microprogramma, in contrasto con il termine: "architettura" che era visibile e documentata per i programmatori. Mentre l'architettura di solito doveva essere compatibile tra le generazioni di hardware, la microarchitettura sottostante poteva essere facilmente cambiata.
Relazione con l'architettura del set di istruzioni
La microarchitettura è collegata, ma non è la stessa, all'architettura del set di istruzioni. L'architettura del set di istruzioni è vicina al modello di programmazione di un processore come visto da un programmatore di linguaggio assembly o da uno scrittore di compilatori, che include il modello di esecuzione, i registri del processore, le modalità di indirizzo della memoria, i formati di indirizzi e dati, ecc. La microarchitettura (o organizzazione del computer) è principalmente una struttura di livello inferiore e quindi gestisce un gran numero di dettagli che sono nascosti nel modello di programmazione. Descrive le parti interne del processore e come lavorano insieme per implementare la specifica architettonica.
Gli elementi microarchitettonici possono essere qualsiasi cosa, da singole porte logiche, a registri, tabelle di lookup, multiplexer, contatori, ecc., a ALU complete, FPU ed elementi ancora più grandi. Il livello dei circuiti elettronici può, a sua volta, essere suddiviso in dettagli a livello di transistor, come ad esempio quali strutture di base per la costruzione di gate sono utilizzate e quali tipi di implementazione logica (statica/dinamica, numero di fasi, ecc.) sono scelti, oltre al design logico effettivo utilizzato costruito.
Alcuni punti importanti:
- Una singola microarchitettura, specialmente se include il microcodice, può essere usata per implementare molti set di istruzioni differenti, attraverso il cambiamento del control store. Questo però può essere abbastanza complicato, anche quando è semplificato dal microcodice e/o dalle strutture delle tabelle nelle ROM o nei PLA.
- Due macchine possono avere la stessa microarchitettura, e quindi lo stesso schema a blocchi, ma implementazioni hardware completamente diverse. Questo gestisce sia il livello dei circuiti elettronici che ancor più il livello fisico di fabbricazione (sia dei circuiti integrati che dei componenti discreti).
- Macchine con microarchitetture diverse possono avere la stessa architettura di set di istruzioni, e quindi entrambe sono in grado di eseguire gli stessi programmi. Nuove microarchitetture e/o soluzioni circuitali, insieme ai progressi nella produzione di semiconduttori, sono ciò che permette alle nuove generazioni di processori di raggiungere prestazioni più elevate.
Descrizioni semplificate
Una descrizione di alto livello molto semplificata - comune nel marketing - può mostrare solo caratteristiche abbastanza basilari, come le larghezze dei bus, insieme a vari tipi di unità di esecuzione e altri grandi sistemi, come la predizione di ramo e le memorie cache, raffigurati come semplici blocchi - forse con alcuni attributi o caratteristiche importanti annotati. Alcuni dettagli riguardanti la struttura della pipeline (come fetch, decode, assign, execute, write-back) possono talvolta essere inclusi.
Aspetti della microarchitettura
Il pipelined datapath è il design datapath più comunemente usato nella microarchitettura oggi. Questa tecnica è usata nella maggior parte dei moderni microprocessori, microcontrollori e DSP. L'architettura pipeline permette a più istruzioni di sovrapporsi nell'esecuzione, un po' come una catena di montaggio. La pipeline include diverse fasi che sono fondamentali nei progetti di microarchitettura. Alcune di queste fasi includono il fetch delle istruzioni, la decodifica delle istruzioni, l'esecuzione e il write back. Alcune architetture includono altre fasi come l'accesso alla memoria. La progettazione delle pipeline è uno dei compiti centrali della microarchitettura.
Anche le unità di esecuzione sono essenziali per la microarchitettura. Le unità di esecuzione includono le unità logiche aritmetiche (ALU), le unità in virgola mobile (FPU), le unità load/store e la predizione di ramo. Queste unità eseguono le operazioni o i calcoli del processore. La scelta del numero di unità di esecuzione, la loro latenza e il throughput sono importanti compiti di progettazione microarchitettonica. La dimensione, la latenza, il throughput e la connettività delle memorie all'interno del sistema sono anche decisioni di microarchitettura.
Le decisioni di progettazione a livello di sistema, come l'inclusione o meno di periferiche, come i controller di memoria, possono essere considerate parte del processo di progettazione microarchitettonica. Questo include decisioni sul livello di prestazioni e sulla connettività di queste periferiche.
A differenza della progettazione architettonica, dove un livello specifico di prestazioni è l'obiettivo principale, la progettazione microarchitettonica presta maggiore attenzione ad altri vincoli. Si deve prestare attenzione a questioni come:
- Area/costo del chip.
- Consumo energetico.
- Complessità logica.
- Facilità di connessione.
- Fabbricabilità.
- Facilità di debugging.
- Testabilità.
Concetti di micro-architettura
In generale, tutte le CPU, microprocessori a chip singolo o implementazioni multi-chip, eseguono programmi eseguendo i seguenti passi:
- Leggere un'istruzione e decodificarla.
- Trova tutti i dati associati che sono necessari per elaborare l'istruzione.
- Elaborare l'istruzione.
- Scrivi i risultati.
A complicare questa apparentemente semplice serie di passi c'è il fatto che la gerarchia della memoria, che include la cache, la memoria principale e la memoria non volatile come i dischi rigidi, (dove si trovano le istruzioni e i dati del programma) è sempre stata più lenta del processore stesso. Il passo (2) spesso introduce un ritardo (in termini di CPU spesso chiamato "stallo") mentre i dati arrivano sul bus del computer. Una grande quantità di ricerca è stata messa in progetti che evitano questi ritardi il più possibile. Nel corso degli anni, un obiettivo centrale della progettazione è stato quello di eseguire più istruzioni in parallelo, aumentando così la velocità effettiva di esecuzione di un programma. Questi sforzi hanno introdotto strutture logiche e circuitali complicate. In passato queste tecniche potevano essere implementate solo su costosi mainframe o supercomputer a causa della quantità di circuiti necessari per queste tecniche. Con il progresso della produzione di semiconduttori, sempre più di queste tecniche potevano essere implementate su un singolo chip di semiconduttori.
Ciò che segue è una panoramica delle tecniche di micro-architettura che sono comuni nelle moderne CPU.
Scelta del set di istruzioni
La scelta di quale Instruction Set Architecture utilizzare influenza notevolmente la complessità dell'implementazione di dispositivi ad alte prestazioni. Nel corso degli anni, i progettisti di computer hanno fatto del loro meglio per semplificare i set di istruzioni, al fine di consentire implementazioni più performanti, risparmiando sforzi e tempo ai progettisti per caratteristiche che migliorano le prestazioni piuttosto che sprecarli nella complessità del set di istruzioni.
La progettazione dei set di istruzioni è progredita dai tipi CISC, RISC, VLIW, EPIC. Le architetture che si occupano del parallelismo dei dati includono SIMD e Vettori.
Pipelining delle istruzioni
Una delle prime e più potenti tecniche per migliorare le prestazioni è l'uso della pipeline di istruzioni. I primi progetti di processori eseguivano tutti i passi di cui sopra su un'istruzione prima di passare alla successiva. Grandi porzioni della circuiteria del processore erano lasciate inattive ad ogni passo; per esempio, la circuiteria di decodifica delle istruzioni sarebbe stata inattiva durante l'esecuzione e così via.
Le pipeline migliorano le prestazioni permettendo a un certo numero di istruzioni di lavorare attraverso il processore allo stesso tempo. Nello stesso esempio di base, il processore inizierebbe a decodificare (passo 1) una nuova istruzione mentre l'ultima è in attesa di risultati. Questo permetterebbe di avere fino a quattro istruzioni "in volo" contemporaneamente, facendo sembrare il processore quattro volte più veloce. Anche se ogni singola istruzione richiede lo stesso tempo per essere completata (ci sono ancora quattro passi) la CPU nel suo complesso "ritira" le istruzioni molto più velocemente e può essere eseguita ad una velocità di clock molto più alta.
Cache
I miglioramenti nella produzione dei chip hanno permesso di mettere più circuiti sullo stesso chip, e i progettisti hanno iniziato a cercare modi per usarli. Uno dei modi più comuni era quello di aggiungere una quantità sempre maggiore di memoria cache sul chip. La cache è una memoria molto veloce, una memoria a cui si può accedere in pochi cicli rispetto a quelli necessari per parlare con la memoria principale. La CPU include un controller della cache che automatizza la lettura e la scrittura dalla cache, se il dato è già nella cache semplicemente "appare", mentre se non lo è il processore è "in stallo" mentre il controller della cache lo legge.
I design RISC hanno iniziato ad aggiungere cache a metà degli anni '80, spesso solo 4 KB in totale. Questo numero è cresciuto nel tempo, e le CPU tipiche ora hanno circa 512 KB, mentre le CPU più potenti hanno 1 o 2 o anche 4, 6, 8 o 12 MB, organizzati in più livelli di una gerarchia di memoria. In generale, più cache significa più velocità.
Le cache e le pipeline erano un'accoppiata perfetta l'una per l'altra. In precedenza, non aveva molto senso costruire una pipeline che potesse funzionare più velocemente della latenza di accesso della memoria cache off-chip. Usare la memoria cache on-chip, invece, significava che una pipeline poteva funzionare alla velocità della latenza di accesso alla cache, una lunghezza di tempo molto minore. Questo permetteva alle frequenze operative dei processori di aumentare ad un ritmo molto più veloce di quello della memoria off-chip.
Previsione di ramo ed esecuzione speculativa
Gli stalli della pipeline e i lavaggi dovuti ai rami sono le due cose principali che impediscono di raggiungere prestazioni più elevate attraverso il parallelismo a livello di istruzioni. Dal momento in cui il decodificatore di istruzioni del processore ha scoperto di aver incontrato un'istruzione di diramazione condizionale al momento in cui il valore del registro di salto decisivo può essere letto, la pipeline potrebbe essere in stallo per diversi cicli. In media, un'istruzione su cinque eseguita è una diramazione, quindi è una quantità elevata di stallo. Se il ramo viene eseguito, è ancora peggio, poiché tutte le istruzioni successive che erano nella pipeline devono essere lavate.
Tecniche come la predizione di ramo e l'esecuzione speculativa sono usate per ridurre queste penalità di ramo. La predizione delle diramazioni è dove l'hardware fa delle ipotesi educate sul fatto che una particolare diramazione sarà presa. L'ipotesi permette all'hardware di prefetchare le istruzioni senza aspettare la lettura del registro. L'esecuzione speculativa è un ulteriore miglioramento in cui il codice lungo il percorso previsto viene eseguito prima di sapere se il ramo deve essere preso o meno.
Esecuzione fuori ordine
L'aggiunta di cache riduce la frequenza o la durata degli stalli dovuti all'attesa dei dati da recuperare dalla gerarchia della memoria principale, ma non elimina completamente questi stalli. Nei primi progetti una cache miss costringeva il controller della cache a mettere in stallo il processore e ad aspettare. Naturalmente ci può essere qualche altra istruzione nel programma i cui dati sono disponibili nella cache a quel punto. L'esecuzione fuori ordine permette a quell'istruzione pronta di essere processata mentre un'istruzione più vecchia aspetta nella cache, poi riordina i risultati per far sembrare che tutto sia avvenuto nell'ordine programmato.
Superscalare
Anche con tutta la complessità aggiunta e le porte necessarie per supportare i concetti delineati sopra, i miglioramenti nella produzione di semiconduttori hanno presto permesso di utilizzare ancora più porte logiche.
Nello schema qui sopra il processore elabora parti di una singola istruzione alla volta. I programmi del computer potrebbero essere eseguiti più velocemente se più istruzioni fossero processate simultaneamente. Questo è ciò che i processori superscalari ottengono, replicando unità funzionali come le ALU. La replicazione delle unità funzionali è stata resa possibile solo quando l'area del circuito integrato (a volte chiamato "die") di un processore a numero singolo non ha più raggiunto i limiti di ciò che poteva essere prodotto in modo affidabile. Verso la fine degli anni '80, i design superscalari cominciarono ad entrare sul mercato.
Nei progetti moderni è comune trovare due unità di caricamento, una di memorizzazione (molte istruzioni non hanno risultati da memorizzare), due o più unità matematiche intere, due o più unità in virgola mobile e spesso un'unità SIMD di qualche tipo. La logica di emissione delle istruzioni cresce in complessità leggendo un'enorme lista di istruzioni dalla memoria e passandole alle diverse unità di esecuzione che sono inattive in quel momento. I risultati vengono poi raccolti e riordinati alla fine.
Rinominare il registro
La rinominazione dei registri si riferisce a una tecnica utilizzata per evitare un'inutile esecuzione in serie delle istruzioni del programma a causa del riutilizzo degli stessi registri da parte di quelle istruzioni. Supponiamo di avere due gruppi di istruzioni che useranno lo stesso registro, un gruppo di istruzioni viene eseguito per primo per lasciare il registro all'altro gruppo, ma se l'altro gruppo è assegnato a un diverso registro simile entrambi i gruppi di istruzioni possono essere eseguiti in parallelo.
Multiprocesso e multithreading
A causa del crescente divario tra le frequenze operative della CPU e i tempi di accesso alla DRAM, nessuna delle tecniche che migliorano il parallelismo a livello di istruzioni (ILP) all'interno di un programma poteva superare i lunghi stalli (ritardi) che si verificavano quando i dati dovevano essere recuperati dalla memoria principale. Inoltre, i grandi numeri di transistor e le alte frequenze operative necessarie per le tecniche ILP più avanzate richiedevano livelli di dissipazione di potenza che non potevano più essere raffreddati in modo economico. Per queste ragioni, le nuove generazioni di computer hanno iniziato a utilizzare livelli più alti di parallelismo che esistono al di fuori di un singolo programma o thread di programma.
Questa tendenza è talvolta conosciuta come "throughput computing". Questa idea ha avuto origine nel mercato dei mainframe dove l'elaborazione delle transazioni online enfatizzava non solo la velocità di esecuzione di una transazione, ma la capacità di gestire un gran numero di transazioni allo stesso tempo. Con le applicazioni basate sulle transazioni, come l'instradamento di rete e il servizio di siti web, in grande aumento nell'ultimo decennio, l'industria dei computer ha nuovamente enfatizzato i problemi di capacità e di throughput.
Una tecnica di come questo parallelismo si ottiene è attraverso sistemi multiprocessore, sistemi di computer con CPU multiple. In passato questo era riservato ai mainframe di fascia alta, ma ora i server multiprocessori su piccola scala (2-8) sono diventati comuni per il mercato delle piccole imprese. Per le grandi aziende, i multiprocessori su larga scala (16-256) sono comuni. Anche i personal computer con CPU multiple sono apparsi dagli anni '90.
I progressi nella tecnologia dei semiconduttori hanno ridotto le dimensioni dei transistor; sono apparse CPU multicore in cui più CPU sono implementate sullo stesso chip di silicio. Inizialmente utilizzato in chip destinati ai mercati embedded, dove CPU più semplici e più piccole permetterebbero istanziazioni multiple per adattarsi ad un pezzo di silicio. Entro il 2005, la tecnologia dei semiconduttori ha permesso di produrre in volume chip CMP per CPU desktop di fascia alta. Alcuni design, come UltraSPARC T1 hanno usato un design più semplice (scalare, in-ordinato) per poter inserire più processori su un pezzo di silicio.
Recentemente, un'altra tecnica che è diventata più popolare è il multithreading. Nel multithreading, quando il processore deve recuperare dati dalla lenta memoria di sistema, invece di aspettare che i dati arrivino, il processore passa a un altro programma o thread di programma che è pronto per essere eseguito. Anche se questo non velocizza un particolare programma/thread, aumenta il throughput generale del sistema riducendo il tempo in cui la CPU è inattiva.
Concettualmente, il multithreading è equivalente a un cambio di contesto a livello di sistema operativo. La differenza è che una CPU multithreaded può fare un cambio di thread in un ciclo CPU invece delle centinaia o migliaia di cicli CPU che un cambio di contesto normalmente richiede. Questo si ottiene replicando l'hardware di stato (come il file di registro e il contatore di programma) per ogni thread attivo.
Un ulteriore miglioramento è il multithreading simultaneo. Questa tecnica permette alle CPU superscalari di eseguire istruzioni da diversi programmi/threads simultaneamente nello stesso ciclo.
Pagine correlate
- Microprocessore
- Microcontrollore
- Processore multi-core
- Processore di segnale digitale
- Design della CPU
- Datapath
- parallelismo a livello di istruzione (ILP)
Domande e risposte
D: Che cos'è la microarchitettura?
R: La microarchitettura è una descrizione del circuito elettrico di un computer, di un'unità di elaborazione centrale o di un processore di segnali digitali, sufficiente a descrivere completamente il funzionamento dell'hardware.
D: Come si riferiscono gli studiosi a questo concetto?
R: Gli studiosi utilizzano il termine "organizzazione del computer" quando si riferiscono alla microarchitettura.
D: Come si riferiscono a questo concetto le persone dell'industria informatica?
R: Le persone dell'industria informatica dicono più spesso "microarchitettura" quando si riferiscono a questo concetto.
D: Quali sono i due campi che compongono l'architettura dei computer?
R: La microarchitettura e l'architettura del set di istruzioni (ISA) costituiscono insieme il campo dell'architettura dei computer.
D: Che cosa significa ISA?
R: ISA è l'acronimo di Instruction Set Architecture.
D: Cosa significa µarch? R: µArch sta per Microarchitettura.
Articoli correlati
Autore
AlegsaOnline.com Microarchitettura Leandro Alegsa
URL: https://it.alegsaonline.com/art/64586
Fonti
- computer.org : IEEE Computer Society
- extremetech.com : PC Processor Microarchitecture