Rete neurale artificiale
Una rete neurale (chiamata anche ANN o rete neurale artificiale) è una sorta di software per computer, ispirato ai neuroni biologici. I cervelli biologici sono capaci di risolvere problemi difficili, ma ogni neurone è responsabile solo per risol…
Una rete neurale (chiamata anche ANN o rete neurale artificiale) è una sorta di software per computer, ispirato ai neuroni biologici. I cervelli biologici sono capaci di risolvere problemi difficili, ma ogni neurone è responsabile solo per risolvere una parte molto piccola del problema. Allo stesso modo, una rete neurale è composta da cellule che lavorano insieme per produrre un risultato desiderato, anche se ogni singola cellula è responsabile solo della risoluzione di una piccola parte del problema. Questo è un metodo per creare programmi artificialmente intelligenti.
Le reti neurali sono un esempio di apprendimento automatico, dove un programma può cambiare mentre impara a risolvere un problema. Una rete neurale può essere addestrata e migliorata con ogni esempio, ma più grande è la rete neurale, più esempi ha bisogno di eseguire bene, spesso ha bisogno di milioni o miliardi di esempi nel caso del deep learning.
Galleria di immagini
6 Immagini

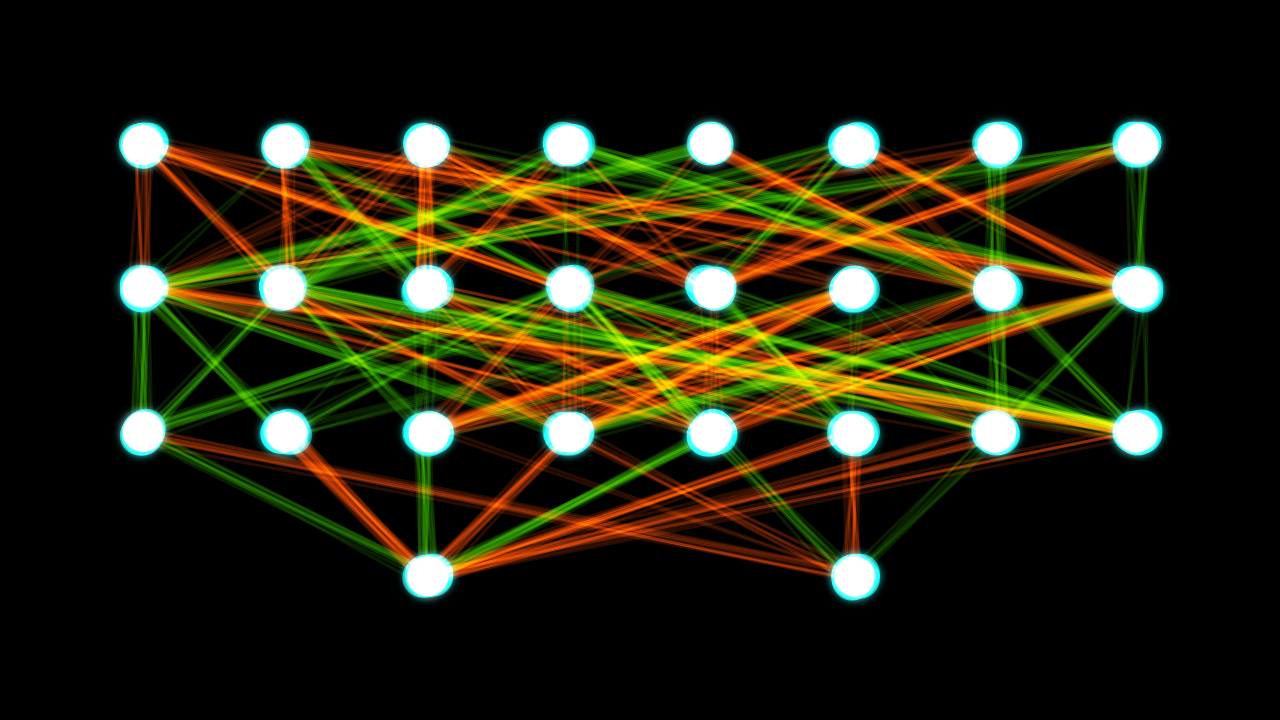



Panoramica
Ci sono due modi di pensare ad una rete neurale. Il primo è come un cervello umano. Il secondo è come un'equazione matematica.
Una rete inizia con un input, un po' come un organo sensoriale. L'informazione scorre poi attraverso strati di neuroni, dove ogni neurone è collegato a molti altri neuroni. Se un particolare neurone riceve abbastanza stimoli, allora invia un messaggio a qualsiasi altro neurone a cui è collegato attraverso il suo assone. Allo stesso modo, una rete neurale artificiale ha uno strato di dati in ingresso, uno o più strati nascosti di classificatori e uno strato di uscita. Ogni nodo in ogni strato nascosto è collegato a un nodo nello strato successivo. Quando un nodo riceve informazioni, ne invia una certa quantità ai nodi a cui è collegato. La quantità è determinata da una funzione matematica chiamata funzione di attivazione, come sigmoide o tanh.
Pensando a una rete neurale come a un'equazione matematica, una rete neurale è semplicemente una lista di operazioni matematiche da applicare a un input. L'input e l'output di ogni operazione è un tensore (o più precisamente un vettore o una matrice). Ogni coppia di strati è collegata da una lista di pesi. Ogni strato ha diversi tensori memorizzati al suo interno. Un singolo tensore in uno strato è chiamato nodo. Ogni nodo è collegato ad alcuni o a tutti i nodi dello strato successivo da un peso. Ogni nodo ha anche una lista di valori chiamati bias. Il valore di ogni strato è quindi il risultato della funzione di attivazione dei valori dello strato corrente (chiamato X) moltiplicato per i pesi.
A t t i v a z i o n e ( W ( e i g h t s ) ∗ X + b ( i a s ) ) {\displaystyle Attivazione(W(eights)*X+b(ias))} 
Una funzione di costo è definita per la rete. La funzione di perdita cerca di stimare quanto bene la rete neurale stia facendo il suo compito assegnato. Infine, viene applicata una tecnica di ottimizzazione per minimizzare l'output della funzione di costo cambiando i pesi e i bias della rete. Questo processo è chiamato allenamento. L'addestramento viene fatto un piccolo passo alla volta. Dopo migliaia di passi, la rete è tipicamente in grado di fare abbastanza bene il suo compito assegnato.
Esempio
Consideriamo un programma che controlla se una persona è viva. Se una persona ha il polso o respira, il programma mostrerà "vivo", altrimenti mostrerà "morto". In un programma che non impara nel tempo, questo verrebbe scritto come:
Una rete neurale molto semplice, fatta di un solo neurone che risolve lo stesso problema avrà questo aspetto:
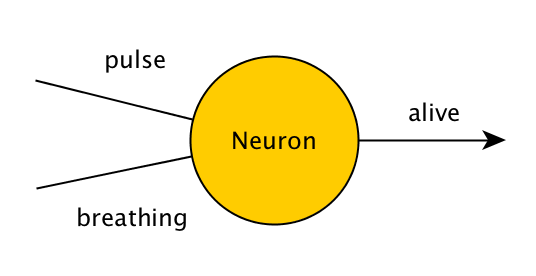
I valori di pulse, breathing e alive saranno 0 o 1, che rappresentano falso e vero. Così, se a questo neurone vengono dati i valori (0,1), (1,0) o (1,1), dovrebbe emettere 1, e se gli viene dato (0,0), dovrebbe emettere 0. Il neurone fa questo applicando una semplice operazione matematica all'input - aggiunge qualsiasi valore che gli è stato dato, e poi aggiunge il proprio valore nascosto, che è chiamato 'bias'. All'inizio, questo valore nascosto è casuale, e lo regoliamo nel tempo se il neurone non ci sta dando l'output desiderato.
Se sommiamo valori come (1,1), potremmo finire con numeri maggiori di 1, ma noi vogliamo che il nostro output sia tra 0 e 1! Per risolvere questo problema, possiamo applicare una funzione che limita il nostro output effettivo a 0 o 1, anche se il risultato dei calcoli del neurone non era nell'intervallo. Nelle reti neurali più complicate, applichiamo una funzione (come la sigmoide) al neurone, in modo che il suo valore sia compreso tra 0 o 1 (come 0,66), e poi passiamo questo valore al neurone successivo fino a quando abbiamo bisogno del nostro output.
Metodi di apprendimento
Ci sono tre modi in cui una rete neurale può imparare: apprendimento supervisionato, apprendimento non supervisionato e apprendimento di rinforzo. Questi metodi funzionano tutti minimizzando o massimizzando una funzione di costo, ma ognuno di essi è migliore in certi compiti.
Recentemente, un team di ricerca dell'Università di Hertfordshire, Regno Unito, ha usato l'apprendimento per rinforzo per far sì che un robot umanoide iCub imparasse a dire parole semplici balbettando.
Domande e risposte
D: Cos'è una rete neurale?
R: Una rete neurale (chiamata anche ANN o rete neurale artificiale) è una sorta di software informatico, ispirato ai neuroni biologici. È composta da cellule che lavorano insieme per produrre un risultato desiderato, anche se ogni singola cellula è responsabile di risolvere solo una piccola parte del problema.
D: In che modo una rete neurale è paragonabile al cervello biologico?
R: I cervelli biologici sono in grado di risolvere problemi difficili, ma ogni neurone è responsabile della risoluzione di una parte molto piccola del problema. Allo stesso modo, una rete neurale è composta da cellule che lavorano insieme per produrre un risultato desiderato, anche se ogni singola cellula è responsabile di risolvere solo una piccola parte del problema.
D: Quale tipo di programma può creare programmi artificialmente intelligenti?
R: Le reti neurali sono un esempio di apprendimento automatico, in cui un programma può cambiare mentre impara a risolvere un problema.
D: Come si può allenare e migliorare con ogni esempio, per utilizzare l'apprendimento profondo?
R: Una rete neurale può essere addestrata e migliorata con ogni esempio, ma più grande è la rete neurale, più esempi ha bisogno per funzionare bene, spesso necessitando di milioni o miliardi di esempi nel caso del deep learning.
D: Di cosa ha bisogno per avere successo l'apprendimento profondo?
R: Affinché l'apprendimento profondo abbia successo, sono necessari milioni o miliardi di esempi, a seconda della dimensione della rete neurale.
D: Che rapporto ha l'apprendimento automatico con la creazione di programmi artificialmente intelligenti?
R: L'apprendimento automatico è correlato alla creazione di programmi artificialmente intelligenti, perché consente ai programmi di cambiare man mano che imparano a risolvere i problemi.
Articoli correlati
Autore
AlegsaOnline.com Rete neurale artificiale Leandro Alegsa
URL: https://it.alegsaonline.com/art/6353
Fonti
- newscientist.com : "Baby robot learns first words from human teacher"