RAID
Contenuti · 1 Introduzione o 1.1 Differenza tra dischi fisici e dischi logici o 1.2 Lettura e scrittura dei dati o 1.3 Cos'è il RAID? o 1.4 Perché usare il RAID? o 1.5 La storia · 2 Concetti di base utilizzati dai sistemi RAID o 2.1 Caching o 2.…
Contenuti
· 1 Introduzione
o 1.1 Differenza tra dischi fisici e dischi logici
o 1.2 Lettura e scrittura dei dati
o 1.3 Cos'è il RAID?
o 1.4 Perché usare il RAID?
o 1.5 La storia
· 2 Concetti di base utilizzati dai sistemi RAID
o 2.1 Caching
o 2.2 Specchiettizzazione: Più di una copia dei dati
o 2.3 Spogliatura: Parte dei dati è su un altro disco
o 2.4 Correzione degli errori e dei guasti
o 2.5 Ricambi a caldo: utilizzare più dischi del necessario
o 2.6 Dimensione delle strisce e dei pezzi: distribuzione dei dati su più dischi
o 2.7 Mettere insieme il disco: JBOD, concatenazione o spaziatura
o 2.8 Clone di azionamento
o 2.9 Diverse configurazioni
· 3 Nozioni di base: livelli RAID semplici
o 3.1 Livelli RAID nell'uso comune
§ 3.1.1 RAID 0 "striping" (striping)
§ 3.1.2 RAID 1 "mirroring" (rispecchiamento)
§ 3.1.3 RAID 5 "striping a parità distribuita".
§ 3.1.4 Immagini
o 3.2 Livelli RAID utilizzati meno
§ 3.2.1 RAID 2
§ 3.2.2 RAID 3 "striping con parità dedicata".
§ 3.2.3 RAID 4 "striping con parità dedicata".
§ 3.2.4 RAID 6
§ 3.2.5 Immagini
o 3.3 Livelli RAID non standard
§ 3.3.1 Doppia parità / Parità diagonale
§ 3.3.2 RAID-DP
§ 3.3.3 RAID 1.5
§ 3.3.4 RAID 5E, RAID 5EE e RAID 6E
§ 3.3.5 RAID 7
§ 3.3.6 Intel Matrix RAID
§ 3.3.7 Driver Linux MD RAID
§ 3.3.8 RAID Z
§ 3.3.9 Immagini
· 4 Unire i livelli RAID
· 5 Fare un RAID
o 5.1 Software RAID
o 5.2 RAID hardware
o 5.3 RAID assistito da hardware
· 6 Diversi termini relativi ai guasti dell'hardware
o 6.1 Tasso di guasto
o 6.2 Tempo medio di perdita dei dati
o 6.3 Tempo medio di recupero
o 6.4 Percentuale di errore di bit non recuperabile
· 7 Problemi con il RAID
o 7.1 Aggiunta di dischi in un secondo momento
o 7.2 Guasti collegati
o 7.3 Atomicità
o 7.4 Dati non recuperabili
o 7.5 Affidabilità della cache di scrittura
o 7.6 Compatibilità delle apparecchiature
· 8 Cosa può e non può fare il RAID
o 8.1 Cosa può fare il RAID
o 8.2 Cosa non può fare il RAID
· 9 Esempio
· 10 Riferimenti
· 11 Altri siti web
RAID è un acronimo che sta per Redundant Array of Inexpensive Disks o Redundant Array of Independent Disks. RAID è un termine usato in informatica. Con RAID, diversi dischi rigidi vengono trasformati in un unico disco logico. Ci sono diversi modi per farlo. Ognuno dei metodi che mette insieme i dischi rigidi ha alcuni vantaggi e svantaggi rispetto all'utilizzo dei dischi come dischi singoli, indipendenti l'uno dall'altro. Le ragioni principali per cui si usa il RAID sono:
- Per rendere meno frequente la perdita di dati. A tal fine è necessario disporre di diverse copie dei dati.
- Per ottenere più spazio di archiviazione avendo molti dischi più piccoli.
- Per ottenere una maggiore flessibilità (i dischi possono essere modificati o aggiunti mentre il sistema continua a funzionare)
- Per ottenere i dati più rapidamente.
Non è possibile raggiungere tutti questi obiettivi contemporaneamente, quindi è necessario fare delle scelte.
Ci sono anche delle brutte cose:
- Alcune scelte possono proteggere contro la perdita di dati a causa del guasto di uno (o di un certo numero) di dischi. Tuttavia, non proteggono dalla cancellazione o dalla sovrascrittura dei dati.
- In alcune configurazioni, il RAID può tollerare che uno o più dischi si guastino. Dopo che i dischi guasti sono stati sostituiti, i dati devono essere ricostruiti. A seconda della configurazione e delle dimensioni dei dischi, questa ricostruzione può richiedere molto tempo.
- Alcuni tipi di errori renderanno impossibile la lettura dei dati
La maggior parte del lavoro sul RAID si basa su un documento scritto nel 1988.
Le aziende hanno utilizzato sistemi RAID per memorizzare i loro dati da quando la tecnologia è stata realizzata. Ci sono diversi modi in cui i sistemi RAID possono essere realizzati. Dalla sua scoperta, il costo della costruzione di un sistema RAID è diminuito molto. Per questo motivo, anche alcuni computer ed elettrodomestici che vengono utilizzati a casa hanno alcune funzioni RAID. Tali sistemi possono essere usati per memorizzare musica o film, per esempio.
Introduzione
Differenza tra dischi fisici e dischi logici
Un disco rigido è una parte di un computer. I normali dischi rigidi usano il magnetismo per memorizzare le informazioni. Quando si usano i dischi rigidi, questi sono a disposizione del sistema operativo. In Microsoft Windows, ogni disco rigido riceverà una lettera di unità (iniziando con C:, A: o B: sono riservati ai dischetti). I sistemi operativi Unix e Linux-like hanno un albero di directory con una sola radice. Ciò significa che le persone che usano i computer a volte non sanno dove sono memorizzate le informazioni (per essere onesti, molti utenti di Windows non sanno dove sono memorizzati i loro dati).
Nell'informatica, i dischi rigidi (che sono hardware, e possono essere toccati) sono talvolta chiamati unità fisiche o dischi fisici. Ciò che il sistema operativo mostra all'utente è talvolta chiamato disco logico. Un'unità fisica può essere divisa in diverse sezioni, chiamate partizioni del disco. Di solito, ogni partizione del disco contiene un unico file system. Il sistema operativo mostra ogni partizione come un disco logico.
Pertanto, per l'utente, sia il setup con molti dischi fisici che quello con molti dischi logici avranno lo stesso aspetto. L'utente non può decidere se un "disco logico" è uguale ad un disco fisico, o se è semplicemente una parte del disco. Le Storage Area Networks (SAN) cambiano completamente questa vista. Tutto ciò che è visibile di una SAN è un numero di dischi logici.
Lettura e scrittura dei dati
Nel computer i dati sono organizzati sotto forma di bit e byte. Nella maggior parte dei sistemi, 8 bit costituiscono un byte. La memoria del computer usa l'elettricità per memorizzare i dati, i dischi rigidi usano il magnetismo. Pertanto, quando i dati sono scritti su un disco, il segnale elettrico viene convertito in un segnale magnetico. Quando i dati vengono letti dal disco, la conversione avviene nell'altra direzione: Un segnale elettrico è fatto dalla polarità di un campo magnetico.
Cos'è il RAID?
Un array RAID unisce due o più dischi rigidi in modo da creare un disco logico. Ci sono diverse ragioni per cui questo viene fatto. I più comuni sono:
- Arrestare la perdita di dati, quando uno o più dischi dell'array si guastano.
- Ottenere trasferimenti di dati più veloci.
- Ottenere la possibilità di cambiare i dischi mentre il sistema continua a funzionare.
- Unendo più dischi per ottenere una maggiore capacità di memorizzazione; a volte vengono utilizzati molti dischi economici, piuttosto che uno più costoso.
Il RAID viene effettuato utilizzando hardware o software speciali sul computer. I dischi rigidi uniti appariranno quindi all'utente come un unico disco rigido. La maggior parte dei livelli RAID aumenta la ridondanza. Ciò significa che essi memorizzano i dati più spesso, oppure memorizzano informazioni su come ricostruire i dati. Questo permette ad un certo numero di dischi di fallire senza che i dati vadano persi. Quando il disco guasto viene sostituito, i dati che dovrebbe contenere saranno copiati o ricostruiti dagli altri dischi del sistema. Questo può richiedere molto tempo. Il tempo necessario dipende da diversi fattori, come la dimensione dell'array.
Perché usare il RAID?
Uno dei motivi per cui molte aziende utilizzano il RAID è che i dati dell'array possono essere semplicemente utilizzati. Coloro che usano i dati non devono necessariamente essere consapevoli che stanno usando il RAID. Quando si è verificato un guasto e l'array si sta ripristinando, l'accesso ai dati sarà più lento. L'accesso ai dati durante questo periodo di tempo rallenterà anche il processo di recupero, ma è comunque molto più veloce che non essere in grado di lavorare con i dati. A seconda del livello RAID, tuttavia, i dischi potrebbero non fallire mentre il nuovo disco viene preparato per l'uso. Un disco che si guasta in quel momento causerà la perdita di tutti i dati dell'array.
I diversi modi di unire i dischi sono chiamati livelli RAID. Un numero maggiore per il livello non è necessariamente migliore. Diversi livelli RAID hanno scopi diversi. Alcuni livelli RAID richiedono dischi speciali e controller speciali.
Storia
Nel 1978, un uomo di nome Norman Ken Ouchi, che lavorava all'IBM, fece un suggerimento descrivendo i piani per quello che sarebbe poi diventato il RAID 5. I piani descrivevano anche qualcosa di simile al RAID 1, così come la protezione di una parte del RAID 4.
I lavoratori dell'Università di Berkeley hanno contribuito a pianificare la ricerca nel 1987. Cercavano di rendere possibile per la tecnologia RAID il riconoscimento di due dischi rigidi invece di uno. Hanno scoperto che quando la tecnologia RAID aveva due dischi rigidi, aveva una capacità di memorizzazione molto migliore rispetto a quella di un solo disco rigido. Tuttavia, si bloccava molto più spesso.
Nel 1988, i diversi tipi di RAID (da 1 a 5), sono stati scritti da David Patterson, Garth Gibson e Randy Katz nel loro articolo, intitolato "A Case for Redundant Arrays of Inexpensive Disks (RAID)". Questo articolo è stato il primo a chiamare la nuova tecnologia RAID e il nome è diventato ufficiale.


Concetti di base utilizzati dai sistemi RAID
Il RAID utilizza alcune idee di base, descritte nell'articolo "RAID: High-Performance, Reliable Secondary Storage" di Peter Chen e altri, pubblicato nel 1994.
Caching
Il caching è una tecnologia che trova impiego anche nei sistemi RAID. Ci sono diversi tipi di cache che vengono utilizzati nei sistemi RAID:
- Sistema operativo
- Controllore RAID
- Enterprise disk array
Nei sistemi moderni, una richiesta di scrittura viene mostrata come si fa quando i dati sono stati scritti nella cache. Ciò non significa che i dati siano stati scritti sul disco. Le richieste provenienti dalla cache non vengono necessariamente gestite nello stesso ordine in cui sono state scritte nella cache. Ciò rende possibile che, in caso di guasto del sistema, a volte alcuni dati non siano stati scritti sul disco interessato. Per questo motivo, molti sistemi hanno una cache supportata da una batteria.
Speculare: Più di una copia dei dati
Quando si parla di uno specchio, questa è un'idea molto semplice. Invece di essere in un solo posto, ci sono diverse copie dei dati. Queste copie di solito si trovano su diversi dischi rigidi (o partizioni del disco). Se ci sono due copie, una di esse può fallire senza che i dati siano interessati (come è ancora sull'altra copia). Il mirroring può anche dare un impulso durante la lettura dei dati. Sarà sempre preso dal disco più veloce che risponde. La scrittura dei dati è però più lenta, perché tutti i dischi devono essere aggiornati.
Spogliarello: Parte dei dati è su un altro disco
Con lo striping, i dati vengono suddivisi in diverse parti. Queste parti finiscono poi su dischi diversi (o partizioni del disco). Ciò significa che la scrittura dei dati è più veloce, poiché può essere effettuata in parallelo. Ciò non significa che non ci saranno errori, in quanto ogni blocco di dati si trova solo su un disco.
Correzione di errori e guasti
È possibile calcolare diversi tipi di checksum. Alcuni metodi di calcolo dei checksum permettono di trovare un errore. La maggior parte dei livelli RAID che utilizzano la ridondanza possono farlo. Alcuni metodi sono più difficili da fare, ma permettono non solo di rilevare l'errore, ma anche di correggerlo.
Ricambi a caldo: utilizzare più dischi del necessario
Molti dei modi per avere il supporto RAID qualcosa si chiama "hot spare". Un hot spare è un disco vuoto che non viene utilizzato nel normale funzionamento. Quando un disco si guasta, i dati possono essere copiati direttamente sul disco di riserva caldo. In questo modo, il disco guasto deve essere sostituito da un nuovo disco vuoto per diventare l'hot spare.
Dimensione delle strisce e dei pezzi: distribuzione dei dati su più dischi
Il RAID funziona diffondendo i dati su diversi dischi. Due dei termini spesso usati in questo contesto sono la dimensione delle strisce e la dimensione dei pezzi.
La dimensione del pezzo è il più piccolo blocco di dati che viene scritto su un singolo disco dell'array. La dimensione della striscia è la dimensione di un blocco di dati che sarà distribuito su tutti i dischi. In questo modo, con quattro dischi, e una dimensione della striscia di 64 kilobyte (kB), 16 kB saranno scritti su ogni disco. La dimensione del pezzo in questo esempio è quindi di 16 kB. Rendere la dimensione della striscia più grande significherà una velocità di trasferimento dati più veloce, ma anche una maggiore latenza massima. In questo caso, questo è il tempo necessario per ottenere un blocco di dati.
Mettere insieme il disco: JBOD, concatenazione o spaziatura
Molti controllori (e anche software) possono mettere insieme i dischi nel modo seguente: Prendono il primo disco, fino alla fine, poi prendono il secondo e così via. In questo modo, diversi dischi più piccoli sembrano più grandi. Questo non è proprio RAID, perché non c'è ridondanza. Inoltre, lo spanning può combinare dischi dove il RAID 0 non può fare nulla. Generalmente, questo si chiama solo un gruppo di dischi (JBOD).
Questo è come un lontano parente del RAID perché l'unità logica è composta da diverse unità fisiche. La concatenazione viene talvolta utilizzata per trasformare diversi piccoli drive in un unico drive utile più grande. Questo non può essere fatto con il RAID 0. Per esempio, JBOD potrebbe combinare unità da 3 GB, 15 GB, 5,5 GB e 12 GB in un'unità logica a 35,5 GB, che spesso è più utile delle sole unità.
Nel diagramma a destra, i dati sono concatenati dalla fine del disco 0 (blocco A63) all'inizio del disco 1 (blocco A64); fine del disco 1 (blocco A91) all'inizio del disco 2 (blocco A92). Se si usava il RAID 0, allora il disco 0 e il disco 2 sarebbero troncati a 28 blocchi, la dimensione del più piccolo disco nell'array (disco 1) per una dimensione totale di 84 blocchi.
Alcuni controllori RAID utilizzano JBOD per parlare del lavoro su unità senza funzioni RAID. Ogni unità viene visualizzata separatamente nel sistema operativo. Questo JBOD non è lo stesso della concatenazione.
Molti sistemi Linux usano i termini "modalità lineare" o "modalità append". L'implementazione di Mac OS X 10.4 - chiamata "Concatenated Disk Set" - non lascia all'utente alcun dato utilizzabile sulle unità rimanenti se un'unità si guasta in un set di dischi concatenati, anche se i dischi funzionano altrimenti come descritto sopra.
La concatenazione è uno degli usi del Logical Volume Manager in Linux. Può essere utilizzato per creare unità virtuali.
Clone di azionamento
La maggior parte dei dischi rigidi moderni ha uno standard chiamato Self-Monitoring, Analysis and Reporting Technology (S.M.A.R.T.). SMART permette di monitorare alcune cose su un disco rigido. Alcuni controllori permettono di sostituire un singolo disco rigido anche prima che si guasti, ad esempio perché S.M.A.R.T. o un altro disco di test riporta troppi errori correggibili. Per fare questo, il controller copia tutti i dati su un disco di riserva caldo. Dopo questo, il disco può essere sostituito da un altro (che diventerà semplicemente il nuovo hot spare).
Diverse configurazioni
La configurazione dei dischi e il modo in cui utilizzano le tecniche sopra descritte influisce sulle prestazioni e sull'affidabilità del sistema. Quando si usano più dischi, uno dei dischi ha più probabilità di fallire. Per questo motivo è necessario costruire dei meccanismi per poter trovare e correggere gli errori. Questo rende l'intero sistema più affidabile, in quanto è in grado di sopravvivere e di riparare il guasto.

Nozioni di base: livelli RAID semplici
Livelli RAID nell'uso comune
RAID 0 "striping" (striping)
Il RAID 0 non è veramente RAID perché non è ridondante. Con RAID 0, i dischi vengono semplicemente messi insieme per creare un disco di grandi dimensioni. Questo si chiama "striping". Quando un disco fallisce, l'intero array fallisce. Pertanto, il RAID 0 è raramente usato per i dati importanti, ma la lettura e la scrittura dei dati dal disco può essere più veloce con lo striping perché ogni disco legge parte del file allo stesso tempo.
Con RAID 0, i blocchi di dischi che si susseguono di solito sono posizionati su dischi diversi. Per questo motivo, tutti i dischi utilizzati da un RAID 0 dovrebbero avere la stessa dimensione.
RAID 0 è spesso usato per Swapspace su sistemi operativi Linux o Unix-like.
RAID 1 "mirroring" (mirroring)
Con RAID 1, si mettono insieme due dischi. Entrambi contengono gli stessi dati, uno è "mirroring" dell'altro. Questa è una configurazione facile e veloce, sia che venga implementata con un controller hardware che con un software.
RAID 5 "striping a parità distribuita".
Il livello 5 del RAID è quello che probabilmente viene utilizzato la maggior parte delle volte. Sono necessari almeno tre dischi rigidi per costruire un array di storage RAID 5. Ogni blocco di dati sarà memorizzato in tre posti diversi. Due di questi posti memorizzeranno il blocco così com'è, il terzo memorizzerà un checksum. Questo checksum è un caso speciale di un codice Reed-Solomon che usa solo l'aggiunta di bit. Di solito, viene calcolato utilizzando il metodo XOR. Poiché questo metodo è simmetrico, un blocco di dati perso può essere ricostruito dall'altro blocco di dati e dalla somma di controllo. Per ogni blocco, un disco diverso terrà il blocco di parità che contiene la somma di controllo. Questo viene fatto per aumentare la ridondanza. Qualsiasi disco può fallire. Nel complesso, ci sarà un solo disco che trattiene la somma di controllo, quindi la capacità totale utilizzabile sarà quella di tutti i dischi tranne uno. La dimensione del disco logico risultante sarà la dimensione di tutti i dischi insieme, ad eccezione di un disco che contiene le informazioni di parità.
Naturalmente questo è più lento del livello RAID 1, poiché in ogni scrittura, tutti i dischi devono essere letti per calcolare e aggiornare le informazioni di parità. Le prestazioni di lettura del RAID 5 sono quasi pari a quelle del RAID 0 per lo stesso numero di dischi. Ad eccezione dei blocchi di parità, la distribuzione dei dati sui dischi segue lo stesso schema del RAID 0. Il motivo per cui il RAID 5 è leggermente più lento è che i dischi devono saltare i blocchi di parità.
Un RAID 5 con un disco guasto continuerà a funzionare. È in modalità degradata. Un RAID 5 degradato può essere molto lento. Per questo motivo viene spesso aggiunto un disco aggiuntivo. Questo si chiama disco di riserva caldo. Se un disco si guasta, i dati possono essere ricostruiti direttamente sul disco aggiuntivo. Il RAID 5 può anche essere fatto in software abbastanza facilmente.
Principalmente a causa di problemi di prestazioni degli array RAID 5 falliti, alcuni esperti di database hanno formato un gruppo chiamato BAARF-La battaglia contro qualsiasi Raid Five.
Se il sistema si guasta mentre sono attive le scritture, la parità di una striscia può diventare incompatibile con i dati. Se questo non viene riparato prima che un disco o un blocco si guasti, può verificarsi una perdita di dati. Una parità non corretta verrà utilizzata per ricostruire il blocco mancante in quella striscia. Questo problema è talvolta noto come "foro di scrittura". Le cache a batteria e tecniche simili sono comunemente usate per ridurre la possibilità che questo si verifichi.
Immagini
· 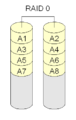
RAID 0 mette semplicemente i diversi blocchi sui diversi dischi. Non c'è ridondanza.
· 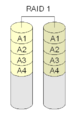
Con Raid 1 ogni blocco è presente su entrambi i dischi
· 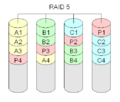
RAID 5 calcola dei checksum speciali per i dati. Sia i blocchi con il checksum che quelli con i dati sono distribuiti su tutti i dischi.
Livelli RAID utilizzati meno
RAID 2
Questo è stato utilizzato con computer molto grandi. Per utilizzare il RAID di livello 2 sono necessari dischi speciali e costosi e un controller speciale. I dati sono distribuiti a livello di bit (tutti gli altri livelli usano azioni a livello di byte). Vengono fatti calcoli speciali. I dati sono suddivisi in sequenze statiche di bit. Vengono messi insieme 8 bit di dati e 2 bit di parità. Poi viene calcolato un codice Hamming. I frammenti del codice di Hamming vengono poi distribuiti sui diversi dischi.
RAID 2 è l'unico livello RAID in grado di riparare gli errori, gli altri livelli RAID possono solo rilevarli. Quando scoprono che le informazioni necessarie non hanno senso, le ricostruiscono semplicemente. Questo viene fatto con i calcoli, utilizzando le informazioni sugli altri dischi. Se queste informazioni sono mancanti o sbagliate, non possono fare molto. Poiché utilizza i codici di Hamming, il RAID 2 può scoprire quale parte dell'informazione è sbagliata, e correggere solo quella parte.
Il RAID 2 ha bisogno di almeno 10 dischi per funzionare. A causa della sua complessità e della sua necessità di hardware molto costoso e speciale, il RAID 2 non è più molto utilizzato.
RAID 3 "striping con parità dedicata".
Il Raid di livello 3 è molto simile al RAID di livello 0. Viene aggiunto un disco aggiuntivo per memorizzare le informazioni di parità. Questo viene fatto tramite l'aggiunta bitwise del valore di un blocco sugli altri dischi. Le informazioni di parità sono memorizzate su un disco separato (dedicato). Questo non va bene, perché se il disco di parità si blocca, l'informazione di parità viene persa.
Il livello 3 del RAID è di solito fatto con almeno 3 dischi. Una configurazione a due dischi è identica ad un RAID di livello 0.
RAID 4 "striping con parità dedicata".
Questo è molto simile al RAID 3, tranne per il fatto che le informazioni di parità sono calcolate su blocchi più grandi, e non su singoli byte. Questo è come il RAID 5. Sono necessari almeno tre dischi per un array RAID 4.
RAID 6
Il livello RAID 6 non era un livello RAID originale. Aggiunge un ulteriore blocco di parità ad un array RAID 5. Ha bisogno di almeno quattro dischi (due dischi per la capacità, due dischi per la ridondanza). Il RAID 5 può essere visto come un caso speciale di codice Reed-Solomon. RAID 5 è un caso speciale, anche se ha bisogno di essere aggiunto solo nel campo GF(2) di Galois. Questo è facile da fare con gli XOR. RAID 6 estende questi calcoli. Non è più un caso speciale, e tutti i calcoli devono essere fatti. Con RAID 6, si usa un checksum extra (chiamato polinomio), di solito di GF (28). Con questo approccio è possibile proteggere da un numero qualsiasi di dischi difettosi. RAID 6 è per il caso di usare due checksum per proteggere dalla perdita di due dischi.
Come per il RAID 5, la parità e i dati sono su dischi diversi per ogni blocco. Anche i due blocchi di parità si trovano su dischi diversi.
Ci sono diversi modi di fare RAID 6. Sono diversi nelle loro prestazioni di scrittura e nella quantità di calcoli necessari. Essere in grado di fare scritture più veloci di solito significa che sono necessari più calcoli.
Il RAID 6 è più lento del RAID 5, ma permette al RAID di continuare con due dischi qualsiasi falliti. Il RAID 6 sta diventando popolare perché permette di ricostruire un array dopo un guasto di un singolo disco anche se uno dei dischi rimanenti ha uno o più settori difettosi.
Immagini
· 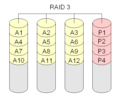
RAID 3 è molto simile al livello RAID 0. Viene aggiunto un disco extra che contiene una somma di controllo per ogni blocco di dati.
· 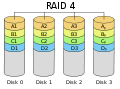
RAID 4 è simile al livello RAID 3, ma calcola la parità su blocchi di dati più grandi
· 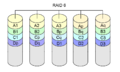
Il RAID 6 è simile al RAID 5, ma calcola due diversi checksum. Questo permette a due dischi di fallire, senza perdita di dati.
Livelli RAID non standard
Doppia parità / Parità diagonale
RAID 6 utilizza due blocchi di parità. Questi sono calcolati in modo speciale su un polinomio. Il RAID a doppia parità (chiamato anche RAID a parità diagonale) utilizza un polinomio diverso per ciascuno di questi blocchi di parità. Recentemente, l'associazione di settore che ha definito il RAID ha detto che il RAID a doppia parità è una forma diversa di RAID 6.
RAID-DP
RAID-DP è un altro modo per avere una doppia parità.
RAID 1.5
RAID 1.5 (da non confondere con RAID 15, che è diverso) è un'implementazione RAID proprietaria. Come il RAID 1, usa solo due dischi, ma fa sia lo striping che il mirroring (simile al RAID 10). La maggior parte delle cose sono fatte in hardware.
RAID 5E, RAID 5EE e RAID 6E
RAID 5E, RAID 5EE e RAID 6E (con l'aggiunta della E per Enhanced) si riferiscono generalmente a diversi tipi di RAID 5 o RAID 6 con un ricambio a caldo. Con queste implementazioni, l'unità hot spare non è un'unità fisica. Piuttosto, esiste sotto forma di spazio libero sui dischi. Questo aumenta le prestazioni, ma significa che un hot spare non può essere condiviso tra diversi array. Lo schema è stato introdotto da IBM ServeRAID intorno al 2001.
RAID 7
Si tratta di un'implementazione proprietaria. Aggiunge il caching ad un array RAID 3 o RAID 4.
Intel Matrix RAID
Alcune schede principali Intel hanno chip RAID che hanno questa caratteristica. Utilizza due o tre dischi, e poi li partiziona ugualmente per formare una combinazione di livelli RAID 0, RAID 1, RAID 5 o RAID 1+0.
Driver RAID MD Linux
Questo è il nome del driver che permette di fare RAID software con Linux. Oltre ai normali livelli RAID 0-6, ha anche un'implementazione RAID 10. Dal Kernel 2.6.9, RAID 10 è un livello unico. L'implementazione ha alcune caratteristiche non standard.
RAID Z
Sun ha implementato un file system chiamato ZFS. Questo file system è ottimizzato per la gestione di grandi quantità di dati. Esso include un Logical Volume Manager. Include anche una funzione chiamata RAID-Z. Evita il problema chiamato RAID 5 write hole perché ha una politica di copia su scrittura: Non sovrascrive direttamente i dati, ma ne scrive di nuovi in una nuova posizione sul disco. Quando la scrittura ha avuto successo, i vecchi dati vengono cancellati. Evita la necessità di operazioni di lettura-modifica-scrittura per le piccole scritture, perché scrive solo a righe intere. I piccoli blocchi sono specchiati al posto della protezione di parità, il che è possibile perché il file system conosce il modo in cui è organizzata la memorizzazione. Può quindi assegnare spazio extra se necessario. Esiste anche RAID-Z2 che utilizza due forme di parità per ottenere risultati simili al RAID 6: la capacità di sopravvivere fino a due guasti del disco senza perdere dati.
Immagini
· 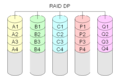
Schema di una configurazione RAID DP (doppia parità).
· 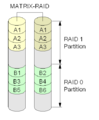
Una configurazione RAID a matrice.
Unirsi ai livelli RAID
Con il RAID si possono mettere insieme diversi dischi per ottenere un disco logico, l'utente vedrà solo il disco logico. Ognuno dei livelli RAID sopra citati ha buoni e cattivi punti. Ma il RAID può funzionare anche con i dischi logici. In questo modo uno dei livelli RAID di cui sopra può essere usato con un insieme di dischi logici. Molte persone lo notano scrivendo i numeri insieme. A volte, scrivono un '+' o un '&' nel mezzo. Le combinazioni comuni (utilizzando due livelli) sono le seguenti:
- RAID 0+1: Due o più array RAID 0 sono combinati in un array RAID 1; Questo è chiamato Mirror of stripes
- RAID 1+0: Uguale al RAID 0+1, ma livelli RAID invertiti; Striscia di specchi. Questo rende il guasto del disco più raro del RAID 0+1 di cui sopra.
- RAID 5+0: Stripe diversi RAID 5 con un RAID 0. Un disco di ogni RAID 5 può fallire, ma fa di quel RAID 5 il singolo punto di guasto; se un altro disco di quell'array fallisce, tutti i dati dell'array andranno persi.
- RAID 5+1: Mirror un insieme di RAID 5: In una situazione in cui il RAID è composto da sei dischi, tre qualsiasi possono fallire (senza che i dati vadano persi).
- RAID 6+0: Stripe diversi array RAID 6 su un RAID 0; due dischi di ogni RAID 6 possono fallire senza perdita di dati.
Con sei dischi da 300 GB ciascuno, per una capacità totale di 1,8 TB, è possibile realizzare un RAID 5, con uno spazio utilizzabile di 1,5 TB. In questo array, un disco può fallire senza perdita di dati. Con RAID 50, lo spazio è ridotto a 1,2 TB, ma un disco di ogni RAID 5 può fallire, oltre a un notevole aumento delle prestazioni. Il RAID 51 riduce le dimensioni utilizzabili a 900 GB, ma consente il guasto di tre unità qualsiasi.
· 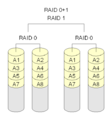
RAID 0+1: diversi array RAID 0 sono combinati con un RAID 1
· 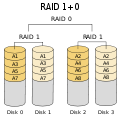
RAID 1+0: più robusto del RAID 0+1; supporta guasti di più unità, a patto che non ci siano due unità che fanno fallire un mirror.
· 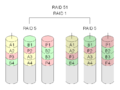
RAID 5+1: Qualsiasi tre unità di questo può fallire, senza perdita di dati.
Fare un RAID
Ci sono diversi modi per fare un RAID. Può essere fatto sia con il software, sia con l'hardware.
Software RAID
Un RAID può essere realizzato con il software in due modi diversi. Nel caso del RAID software, i dischi sono collegati come i normali dischi rigidi. È il computer che fa funzionare il RAID. Ciò significa che per ogni accesso la CPU deve anche fare i calcoli per il RAID. I calcoli per il RAID 0 o RAID 1 sono semplici. Tuttavia, i calcoli per il RAID 5, RAID 6, o uno dei livelli RAID combinati possono essere molto impegnativi. In un RAID software, l'avvio automatico da un array che non è riuscito può essere una cosa difficile da fare. Infine, il modo in cui il RAID viene fatto nel software dipende dal sistema operativo utilizzato; generalmente non è possibile ricostruire un array RAID software con un sistema operativo diverso. I sistemi operativi di solito usano partizioni di dischi rigidi piuttosto che interi dischi rigidi per creare array RAID.
RAID hardware
Un RAID può essere realizzato anche con hardware. In questo caso si usa un controller speciale per dischi; questa scheda controller nasconde il fatto che sta facendo RAID al sistema operativo e all'utente. I calcoli delle informazioni del checksum, e altri calcoli relativi al RAID sono fatti su uno speciale microchip in quel controller. Questo rende il RAID indipendente dal sistema operativo. Il sistema operativo non vedrà il RAID, vedrà un singolo disco. Produttori diversi fanno il RAID in modi diversi. Questo significa che un RAID costruito con un controller RAID hardware non può essere ricostruito da un altro controller RAID di un altro produttore. I controller RAID hardware sono spesso costosi da acquistare.
RAID assistito da hardware
Si tratta di un mix tra RAID hardware e RAID software. Il RAID assistito dall'hardware utilizza uno speciale chip di controllo (come il RAID hardware), ma questo chip non può fare molte operazioni. È attivo solo all'avvio del sistema; non appena il sistema operativo è completamente caricato, questa configurazione è come il RAID software. Alcune schede madri hanno funzioni RAID per i dischi collegati; il più delle volte queste funzioni RAID vengono eseguite come RAID hardware-assistito. Ciò significa che è necessario un software speciale per poter utilizzare queste funzioni RAID ed essere in grado di recuperare da un disco guasto.
Diversi termini relativi ai guasti dell'hardware
Ci sono diversi termini che vengono utilizzati quando si parla di guasti all'hardware:
Tasso di fallimento
Il tasso di guasto è la frequenza con cui un sistema si guasta. Il tempo medio di guasto (MTTF) o il tempo medio tra i guasti (MTBF) di un sistema RAID è lo stesso di quello dei suoi componenti. Un sistema RAID non può proteggere dai guasti dei suoi singoli dischi rigidi, dopo tutto. I tipi di RAID più complicati (tutto ciò che va oltre lo "striping" o la "concatenazione") possono però aiutare a mantenere i dati intatti anche se un singolo disco rigido si guasta.
Tempo medio di perdita di dati
Il tempo medio di perdita di dati (MTTDL) fornisce il tempo medio prima che si verifichi una perdita di dati in un dato array. Il tempo medio di perdita di dati di un dato RAID può essere superiore o inferiore a quello dei suoi dischi rigidi. Questo dipende dal tipo di RAID utilizzato.
Tempo medio di recupero
Gli array che hanno una ridondanza possono recuperare da alcuni guasti. Il tempo medio di recupero mostra quanto tempo ci vuole prima che un array fallito torni al suo stato normale. Questo aggiunge sia il tempo per sostituire un meccanismo di disco guasto sia il tempo per ricostruire l'array (cioè per replicare i dati per la ridondanza).
Tasso di errore di bit non recuperabile
Il bit error rate non recuperabile (UBE) indica per quanto tempo un'unità disco non sarà in grado di recuperare i dati dopo aver utilizzato i codici di controllo di ridondanza ciclica (CRC) e i tentativi multipli.
Problemi con il RAID
Ci sono anche alcuni problemi con le idee o la tecnologia alla base del RAID:
Aggiunta di dischi in un secondo momento
Alcuni livelli RAID permettono di estendere l'array semplicemente aggiungendo dischi rigidi, in un secondo momento. Informazioni come i blocchi di parità sono spesso sparse su diversi dischi. L'aggiunta di un disco all'array rende necessaria una riorganizzazione. Una tale riorganizzazione è come una ricostruzione dell'array, può richiedere molto tempo. Quando questo viene fatto, lo spazio aggiuntivo potrebbe non essere ancora disponibile, perché sia il file system sull'array, sia il sistema operativo hanno bisogno di essere informati. Alcuni file system non supportano la crescita dopo la loro creazione. In tal caso, tutti i dati devono essere sottoposti a backup, l'array deve essere ricreato con il nuovo layout e i dati devono essere ripristinati su di esso.
Un'altra opzione per aggiungere lo storage è quella di creare un nuovo array e di lasciare che sia un gestore di volumi logici a gestire la situazione. Questo permette di far crescere quasi ogni sistema RAID, anche RAID1 (che da solo è limitato a due dischi).
Guasti collegati
Il meccanismo di correzione degli errori nel RAID presuppone che i guasti delle unità siano indipendenti. È possibile calcolare la frequenza con cui un'apparecchiatura può guastarsi e organizzare l'array in modo da rendere molto improbabile la perdita di dati.
In pratica, tuttavia, le unità sono state spesso acquistate insieme. Hanno all'incirca la stessa età, e sono stati usati in modo simile (chiamato usura). Molti azionamenti si guastano a causa di problemi meccanici. Più un azionamento è vecchio, più sono usurate le sue parti meccaniche. Le parti meccaniche che sono vecchie hanno più probabilità di guastarsi rispetto a quelle più giovani. Ciò significa che i guasti degli azionamenti non sono più statisticamente indipendenti. In pratica, c'è la possibilità che anche un secondo disco si guasti prima che il primo sia stato recuperato. Ciò significa che la perdita di dati può verificarsi a velocità significative, in pratica.
Atomicità
Un altro problema che si verifica anche con i sistemi RAID è che le applicazioni si aspettano quella che viene chiamata Atomicità: O tutti i dati sono scritti, o nessuno lo è. La scrittura dei dati è nota come transazione.
Negli array RAID, i nuovi dati vengono solitamente scritti nel luogo in cui si trovavano i vecchi dati. Questo è diventato noto come aggiornamento sul posto. Jim Gray, un ricercatore di database, ha scritto un articolo nel 1981 in cui descriveva questo problema.
Pochissimi sistemi di memorizzazione permettono la semantica di scrittura atomica. Quando un oggetto viene scritto su disco, un dispositivo di memorizzazione RAID di solito scrive tutte le copie dell'oggetto in parallelo. Molto spesso, c'è un solo processore responsabile della scrittura dei dati. In tal caso, le scritture dei dati sui diversi drive si sovrappongono. Questo è noto come scrittura sovrapposta o scrittura sfalsata. Un errore che si verifica durante il processo di scrittura può quindi lasciare le copie ridondanti in diversi stati. Quel che è peggio, può lasciare le copie non nel vecchio o nel nuovo stato. La registrazione si basa però sul fatto che i dati originali si trovino nel vecchio o nel nuovo stato. Questo permette di eseguire il backup del cambiamento logico, ma pochi sistemi di memorizzazione forniscono una scrittura semantica atomica su un disco RAID.
L'utilizzo di una cache di scrittura a batteria può risolvere questo problema, ma solo in caso di mancanza di corrente.
Il supporto transazionale non è presente in tutti i controller RAID hardware. Pertanto, molti sistemi operativi lo includono per proteggere dalla perdita di dati durante una scrittura interrotta. Novell Netware, a partire dalla versione 3.x, include un sistema di tracciamento delle transazioni. Microsoft ha introdotto il tracciamento delle transazioni tramite la funzione di journaling in NTFS. Il file system WAFL di NetApp lo risolve non aggiornando mai i dati sul posto, così come ZFS.
Dati non recuperabili
Alcuni settori su un disco rigido possono essere diventati illeggibili a causa di un errore. Alcune implementazioni RAID possono affrontare questa situazione spostando i dati altrove e contrassegnando il settore sul disco come difettoso. Questo accade a circa 1 bit nel 1015 nelle unità disco di classe enterprise, e a 1 bit nel 1014 nelle normali unità disco. Le capacità del disco sono in costante aumento. Questo può significare che a volte, un RAID non può essere ricostruito, perché un tale errore viene trovato quando l'array viene ricostruito dopo un guasto del disco. Alcune tecnologie come il RAID 6 cercano di risolvere questo problema, ma soffrono di una penalità di scrittura molto alta, in altre parole la scrittura dei dati diventa molto lenta.
Affidabilità della cache di scrittura
Il sistema di dischi può riconoscere l'operazione di scrittura non appena i dati si trovano nella cache. Non è necessario attendere che i dati siano stati scritti fisicamente. Tuttavia, un'eventuale interruzione di corrente può significare una significativa perdita di dati di tutti i dati accodati in tale cache.
Con il RAID hardware è possibile utilizzare una batteria per proteggere questa cache. Questo spesso risolve il problema. Quando l'alimentazione viene a mancare, il controllore può finire di scrivere la cache quando l'alimentazione è tornata. Questa soluzione può comunque fallire: la batteria può essersi consumata, l'alimentazione può essere stata spenta per troppo tempo, i dischi possono essere spostati su un altro controller, il controller stesso può fallire. Alcuni sistemi possono fare controlli periodici della batteria, ma questi utilizzano la batteria stessa, e la lasciano in uno stato in cui non è completamente carica.
Compatibilità delle apparecchiature
I formati dei dischi su diversi controller RAID non sono necessariamente compatibili. Pertanto, potrebbe non essere possibile leggere un array RAID su hardware diverso. Di conseguenza, un guasto dell'hardware non disco può richiedere l'utilizzo di hardware identico, o un backup, per recuperare i dati.
Cosa può e non può fare il RAID
Questa guida è stata tratta da un thread di un forum sul RAID. Questo è stato fatto per aiutare a sottolineare i vantaggi e gli svantaggi della scelta del RAID. Si rivolge alle persone che vogliono scegliere il RAID sia per l'aumento delle prestazioni che per la ridondanza. Contiene link ad altre discussioni nel suo forum che contengono recensioni aneddotiche generate dagli utenti sulle loro esperienze RAID.
Cosa può fare il RAID
- Il RAID può proteggere il tempo di attività. I livelli RAID 1, 0+1/10, 5 e 6 (e le loro varianti come 50 e 51) compensano un guasto meccanico del disco rigido. Anche dopo il guasto del disco, i dati sull'array possono comunque essere utilizzati. Invece di un lungo ripristino da nastro, DVD o altri supporti di backup lenti, il RAID consente di ripristinare i dati su un disco sostitutivo degli altri membri dell'array. Durante questo processo di ripristino, è disponibile per gli utenti in uno stato degradato. Questo è molto importante per le imprese, poiché i tempi di inattività portano rapidamente alla perdita di potenza di guadagno. Per gli utenti domestici, è in grado di proteggere i tempi di attività dei grandi array di archiviazione dei media, che richiederebbero un restauro dispendioso in termini di tempo da decine di DVD o da un bel po' di nastri in caso di guasto di un disco che non è protetto da ridondanza.
- Il RAID può aumentare le prestazioni in alcune applicazioni. I livelli RAID 0, 5 e 6 utilizzano tutti lo striping. Questo permette a più mandrini di aumentare le velocità di trasferimento per i trasferimenti lineari. Le applicazioni di tipo workstation spesso lavorano con file di grandi dimensioni. Esse traggono grande beneficio dallo striping del disco. Esempi di tali applicazioni sono quelle che utilizzano file video o audio. Questo throughput è utile anche nei backup da disco a disco. Il RAID 1, così come altri livelli RAID basati sullo striping, possono migliorare le prestazioni per i modelli di accesso con molti accessi casuali simultanei, come quelli utilizzati da un database multiutente.
Cosa non può fare il RAID
- Il RAID non può proteggere i dati sull'array. Un array RAID ha un unico file system. Questo crea un unico punto di errore. Ci sono molte cose che possono accadere a questo file system oltre al guasto del disco fisico. Il RAID non può difendersi da queste fonti di perdita di dati. Il RAID non impedisce a un virus di distruggere i dati. Il RAID non impedirà la corruzione. Il RAID non salva i dati quando un utente li modifica o li cancella per errore. Il RAID non protegge i dati da guasti hardware di qualsiasi componente oltre ai dischi fisici. Il RAID non protegge i dati da disastri naturali o causati dall'uomo, come incendi e inondazioni. Per proteggere i dati, è necessario eseguire il backup su supporti rimovibili, come DVD, nastro o un disco rigido esterno. Il backup deve essere conservato in un luogo diverso. Il RAID da solo non impedirà che un disastro, quando (non se) si verifica, si trasformi in una perdita di dati. I disastri non possono essere evitati, ma i backup consentono di evitare la perdita di dati.
- Il RAID non può semplificare il disaster recovery. Quando si esegue un singolo disco, il disco può essere utilizzato dalla maggior parte dei sistemi operativi in quanto dotato di un comune driver di dispositivo. Tuttavia, la maggior parte dei controller RAID necessitano di driver speciali. Gli strumenti di recupero che funzionano con dischi singoli su controller generici richiedono driver speciali per accedere ai dati sugli array RAID. Se questi strumenti di recupero sono mal codificati e non consentono di fornire driver aggiuntivi, allora un array RAID sarà probabilmente inaccessibile a tale strumento di recupero.
- Il RAID non può fornire un incremento delle prestazioni in tutte le applicazioni. Questa affermazione è particolarmente vera per i tipici utenti di applicazioni desktop e per i giocatori. Per la maggior parte delle applicazioni desktop e dei giochi, la strategia del buffer e la ricerca delle prestazioni del/dei dischetto/i sono più importanti del throughput grezzo. L'aumento della velocità di trasferimento sostenuto del raw mostra pochi guadagni per tali utenti, dato che la maggior parte dei file a cui accedono sono in genere comunque molto piccoli. Lo striping del disco usando il RAID 0 aumenta le prestazioni di trasferimento lineare, non le prestazioni di buffer e seek. Di conseguenza, lo striping del disco con RAID 0 mostra un guadagno di prestazioni minimo o nullo nella maggior parte delle applicazioni desktop e dei giochi, anche se ci sono delle eccezioni. Per gli utenti desktop e i giocatori che hanno come obiettivo alte prestazioni, è meglio acquistare un disco singolo più veloce, più grande e più costoso che eseguire due dischi più lenti/piccoli in RAID 0. Anche facendo funzionare i dischi più recenti, più grandi e più grandi in RAID-0 è improbabile che le prestazioni aumentino più del 10%, e le prestazioni possono diminuire in alcuni modelli di accesso, in particolare nei giochi.
- È difficile spostare il RAID in un nuovo sistema. Con un singolo disco, è relativamente facile spostare il disco in un nuovo sistema. Può essere semplicemente collegato al nuovo sistema, se ha la stessa interfaccia disponibile. Tuttavia, questo non è così facile con un array RAID. C'è un certo tipo di metadati che dice come viene impostato il RAID. Un BIOS RAID deve essere in grado di leggere questi metadati in modo da poter costruire con successo l'array e renderlo accessibile ad un sistema operativo. Poiché i produttori di controller RAID usano formati diversi per i loro metadati (anche controller di famiglie diverse dello stesso produttore possono usare formati di metadati incompatibili) è quasi impossibile spostare un array RAID in un controller diverso. Quando si sposta un array RAID in un nuovo sistema, si dovrebbe pianificare di spostare anche il controller. Con la popolarità dei controller RAID integrati nella scheda madre, questo è estremamente difficile. In generale, è possibile spostare i membri dell'array RAID e i controller insieme. Anche il RAID software in Linux e Windows Server Products può aggirare questa limitazione, ma il RAID software ne ha altri (per lo più legati alle prestazioni).
Esempio
I livelli RAID utilizzati più spesso sono RAID 0, RAID 1 e RAID 5. Supponiamo che ci sia una configurazione a 3 dischi, con 3 dischi identici di 1 TB ciascuno, e la probabilità di guasto di un'unità per un determinato periodo di tempo è dell'1%.
| Livello RAID | Capacità utilizzabile | Probabilità di guasto dato in percentuale | Probabilità di guasto 1 in ... casi fallisce |
| 0 | 3 TB | 2,9701% | 34 |
| 1 | 1 TB | 0,0001% | 1 milione |
| 5 | 2 TB | 0,0298% | 3356 |
Autore
AlegsaOnline.com RAID Leandro Alegsa
URL: https://it.alegsaonline.com/art/80859
Fonti
- www-2.cs.cmu.edu : ""A Case for Redundant Arrays of Inexpensive Disks" - Patterson, Gibson, Katz"
- thomason.org : "RAID: High-Performance, Reliable Secondary Storage"
- baarf.com : "BAARF - Battle Against Any Raid Five"
- media.netapp.com : "RAID-DP™: Network Appliance™ implementation of RAID Double Parity for data protection, a high speed implementation of RAID 6"
- nasi.com : "IBM X-Architecture Technology 2001:A design blueprint for Intel processor-based servers"
- pcguide.com : "RAID Level 7"
- cgi.cse.unsw.edu.au : "Linux RAID 10 driver"
- linux-raid.osdl.org : "Main Page - Linux-raid"
- blogs.sun.com : "RAID-Z : Jeff Bonwick's Blog"
- blogs.sun.com : "Adam Leventhal's Weblog"
- research.microsoft.com : "Empirical Measurements of Disk Failure Rates and Error Rates"
- usenix.org : "Disk Failures in the Real World: What Does an MTTF of 1,000,000 Hours Mean to You?"
- research.microsoft.com : "The Transaction Concept: Virtues and Limitations (Invited Paper)¦format=pdf"
- informatik.uni-trier.de : "VLDB 1981"
- arxiv.org : "Empirical Measurements of Disk Failure Rates and Error Rates"